

Pandasのデータフレームは、Pythonでデータ分析を行うための強力なライブラリです。
今回は、データの一部を見る方法や、データの全体像を理解する方法について、一緒に学んでいきましょう。
データ分析プロジェクトを開始する際の「第一歩」として、データセットに対する理解を深めることができます。

今回、コードはGoogle Colabを使用して書いています。
他のIDE(VS codeなど)を使用した場合、
うまく実行できるか分かりませんので、Google Colabを使用してコードを書いてみてください。
実際に、コピーしたコードを貼り付けて使用してみると分かりやすいと思います。

- df.head()とdf.tail()で全体像を見る方法
- 数値型の列に対する基本統計量(平均値、標準偏差、最小値、最大値など)を表示する方法
- データフレームに関する情報を表示する方法
- 各列のデータ型を表示する方法
- まとめ
データの準備
# pandasをインポートします
import pandas as pd
# 使用するデータを準備します
data = {
"名前": ["しおり", "あきら", "かずや", "あかね", "ゆみか", "たくや", "つよし", "ごろう", "しんご",
"みく", "りょう", "まな", "けいた", "ゆうき", "あおい"],
"年齢": [22, 25, 30, 33, 37, 28, 40, 32, 25, 20, 27, 35, 21, 29, 31],
"場所": ["東京", "東京", "大阪", "愛知", "沖縄", "北海道", "奈良", "京都", "福岡",
"東京", "大阪", "愛知", "福岡", "神奈川", "埼玉"],
"身長": [155, 176, 170, 160, 165, 178, 180, 176, 182, 158, 170, 163, 175, 181, 168],
"体重": [50, 70, 68, 50, 53, 68, 65, 70, 75, 55, 60, 53, 65, 72, 58],
"好きな漫画": ["ワンピース", "ナルト", "スラムダンク", "メジャー", "ドラゴンボール", "海皇紀", "呪術廻戦", "シュート", "キングダム",
"鋼の錬金術師", "進撃の巨人", "鬼滅の刃", "呪術廻戦", "僕のヒーローアカデミア", "SPY×FAMILY"],
"好きな色": ["赤", "青", "黄色", "紫", "白", "ネイビー", "赤", "黒", "ピンク", "緑", "オレンジ", "水色", "黄色", "茶色", "ピンク"],
"好きな食べ物": ["カレー", "ラーメン", "パスタ", "ハンバーグ", "カツ丼", "麻婆豆腐", "寿司", "唐揚げ", "焼肉",
"オムライス", "焼きそば", "お好み焼き", "たこ焼き", "ピザ", "ハンバーガー"],
"国籍": ["日本", "日本", "日本", "日本", "日本", "日本", "日本", "日本", "日本",
"日本", "日本", "日本", "日本", "日本", "日本"],
"仕事": ["ブロガー", "会社員", "学生", "フリーランス", "主婦", "公務員", "医師", "教師", "自営業",
"デザイナー", "エンジニア", "看護師", "美容師", "販売員", "パティシエ"],
}
# pandasデータフレームを作成します
df = pd.DataFrame(data)
# 作成したデータフレームを表示します
df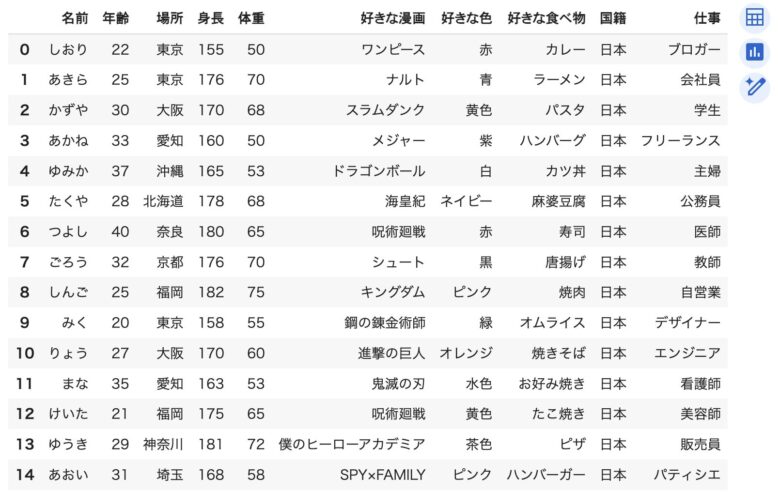
df.head()とdf.tail()で全体像を見てみよう
最初にデータと対面したとき、どこから手を付ければいいのか迷うことがありますよね。
そんな時、Pandasのdf.head()とdf.tail()が役立ちます。
最初と最後のデータを見ることで、データの範囲、変数の種類、欠損値の有無など、分析前の重要な情報を初期段階でキャッチすることが可能になります。
df.head()の使い方:データの「入口」を垣間見る
例えば、あなたが新しい本を手に取ったとき、最初の数ページをパラパラとめくることがないですか?df.head()も同じ役割を果たします。
デフォルトで、データフレームの「最初の5行」を表示してくます。
データの形式や、どんな種類の情報が含まれているのか、初めの一歩として確認することができます。
df.head()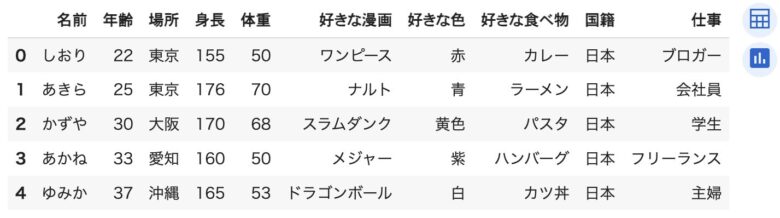
もし「5行よりも多く」見たい場合は、括弧の中に数字を入れるだけです。
例:df.head(10)で最初の10行を表示
df.tail()の使い方:データの「出口」を覗き見る
一方で、物語の終わりに興味を持つこともありますよね。df.tail()はそのためのメソッドです。
これはデフォルトで「最後の5行」を表示します。
データセットがどのように終わっているのか、最後の情報にどんな特徴があるのかを素早く確認できます。
df.tail()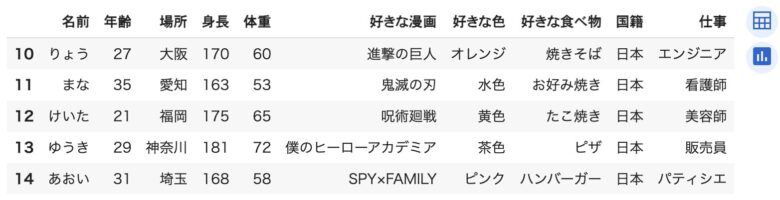
こちらも、もっと多くの行を見たい場合は、括弧の中に数字を入れます。
例:df.tail(10)で最後の10行を表示
数値型の列に対する基本統計量を表示する方法
df.describe()の使い方
df.describe()は数値型の列に含まれるデータについて、特性を一挙に明らかにする魔法のような機能を持っています。
df.describe()を使うことで、データ分析の初期段階において、データセットの概要をつかむことができます。
df.describe()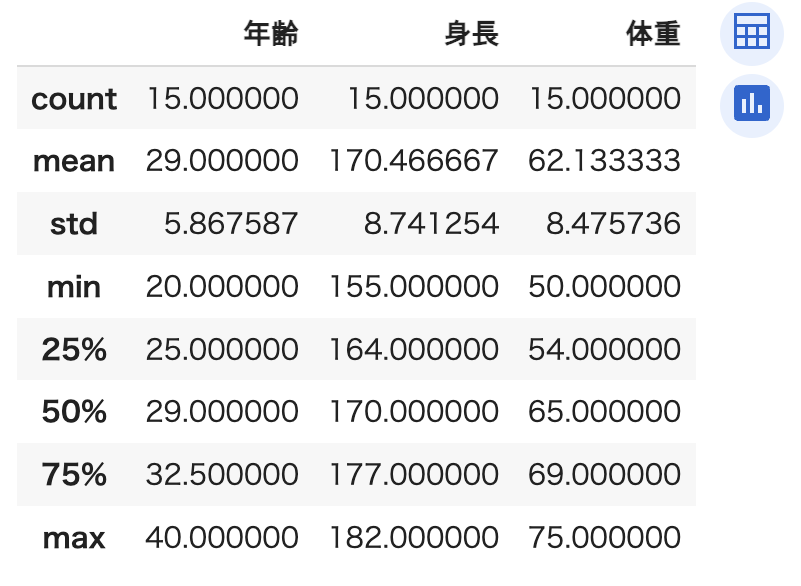
df.describe()で分かる情報
df.describe()を実行すると、以下のような情報が手に入ります。
- count: 各列に含まれるデータの数を示します。これにより、データの量を知ることができます。
- mean: 平均値です。データ全体の「中心」を示します。
- std: 標準偏差です。データが平均値からどれだけ散らばっているかを示す尺度です。
- min: 最小値です。データセット内の最も小さい値を教えてくれます。
- 25%: 第一四分位数です。データセットの下から25%の位置にある値です。
- 50%: 中央値(メディアン)です。データセットを二等分する値です。
- 75%: 第三四分位数です。データセットの上から25%の位置にある値です。
- max: 最大値です。データセット内の最も大きい値を示します。
データ構造を詳しく知る方法
df.info()の使い方
df.info()は、データフレームに含まれる情報の「全体像」を瞬時に提供してくれる、非常に便利なメソッドです。
df.info()を実行すると、以下のような情報が表示されます。
df.info()
df.info()で表示される情報
- Index: データフレームのインデックスの範囲とステップを示します。これは、データセットがどのように整理されているかを教えてくれます。
- Data columns: データフレームに含まれる列の総数です。いくつの異なる種類の情報がデータセットに含まれているかを示します。
- Column entries: 各列の名前とその列に含まれるデータの数、非欠損値の数、そしてデータ型が列挙されます。これにより、どの列がどのような種類のデータを含んでいるか、そして欠損値はどれくらいあるのかが一目でわかります。
- dtypes: データフレームに含まれる異なるデータ型の数を示します。数値型、オブジェクト型(文字列など)、日付時刻型など、データセットにどのような種類のデータが含まれているかを把握できます。
- memory usage: データフレームがメモリ上で占めるサイズを示します。大規模なデータセットを扱う場合、この情報はパフォーマンスの最適化に役立ちます。
データフレームクラスの表示
最初に、<class 'pandas.core.frame.DataFrame'>という情報が表示されます。
これは、あなたが操作しているオブジェクトがPandasのデータフレームであることを示しています。
インデックス情報
RangeIndex: 15 entries, 0 to 14という部分では、データフレームが15行のデータを持っており、インデックスが0から14までの範囲であることを示しています。
これにより、データセットのサイズをすぐに把握できます。
列情報
次に、Data columns (total 10 columns):という部分では、データフレームが合計で10の列を持っていることが示されます。
そして、各列について以下の情報が提供されます。
- Column: 列の名前がリストされ、左側の番号は列の位置を示しています。
- Non-Null Count: 各列に含まれる非欠損値(nullでない値)の数を示します。
ここでは、全ての列が15の非欠損値を持っており、データが完全であることがわかります。 - Dtype: 各列のデータ型を示します。
この例では、int64(整数型)が3列、object(オブジェクト型、通常は文字列や混在型のデータを含む)が7列あります
メモリ使用量 memory usage: 1.3+ KB
最後に、memory usage: 1.3+ KBという情報では、データフレームがメモリ上で約1.3キロバイトを使用していることが示されます。
これにより、データセットのサイズが大きすぎないか、または予期せぬメモリ使用量がないかを確認できます。
各列のデータ型を表示する方法
df.dtypesの使い方
df.dtypesはデータフレーム内の各列のデータ型を表示します。
これにより、どの列が数値型で、どの列がオブジェクト(文字列など)型かを確認できます。
df.dtypes
Pandasでは文字列データを含む列はobject型として扱われ、df.dtypesの出力においてstrと表示されることはありません。
df.dtypesで表示される主要なデータ型
数値型
- int64: 整数型。64ビットの整数を格納できます。
- float64: 浮動小数点型。64ビットの浮動小数点数を格納できます。
- int32, float32: それぞれ32ビットの整数と浮動小数点数を格納できます。メモリ使用量を節約したい場合に有用です。
日付時刻型
- datetime64: 日付と時刻のデータ。
pd.to_datetime関数を使って、文字列などから変換できます。 - timedelta[ns]: 時間の差分を扱います。例えば、日付の差分などを表すのに使われます。
カテゴリ型
- category: 限定された数の可能な値のみを取るデータ型。文字列データの効率的な格納と計算に有用です。
文字列型
- object: 文字列や混在したデータ型(例:文字列と数値が混在する列)を含む列に使用されます。
ブール型
- bool: 真偽値(True/False)を格納するための型です。
まとめ
今回は、データフレームの前処理における内容で
- df.head()とdf.tail()で全体像を見る方法
- 数値型の列に対する基本統計量(平均値、標準偏差、最小値、最大値など)を表示する方法
- データフレームに関する情報を表示する方法
- 各列のデータ型を表示する方法
の順に解説していきました。
データの前処理は、データ分析や機械学習モデルの訓練を行う前に必要なデータを準備し、クリーニングし、整形する一連のプロセスを指します。
これらの初期段階での確認は、後続のデータクリーニング(欠損値の処理、外れ値の検出と処理など)、データ変換(カテゴリデータの数値化、特徴量エンジニアリングなど)、データの正規化や標準化といった前処理ステップに向けた準備段階として機能します。
Pandasのデータフレームを使いこなす上で非常に大切な部分になります。
少しずつ『Pandasの初心者から使える人』に近づいていきましょう。
今回の記事が皆様のお役に立てたら幸いです。

コメント