

こんにちは。タスカです。
今回は、PandasというPythonでデータ分析を行う際の心強い味方について学んでいきましょう。
Pandasのおかげで、複雑そうに見えるデータも、手の中で踊るように扱うことができます。
表形式のデータ、つまり私たちが日常でよく目にするExcelのシートのような形式を、Pandasでは「データフレーム」と呼びます。
本記事はpandasについて理解し、データフレームの基本的な使い方を理解することを目的として書きました。
最後までお付き合い頂いたら幸いです。

今回、コードはGoogle Colabを使用して書いています。
他のIDE(VS codeなど)を使用した場合、
うまく実行できるか分かりませんので、Google Colabを使用してコードを書いてみてください。

- pandasとは?
- データフレームの基礎
- データフレームの作成と操作
- まとめ
Pandasとは?
想像してみてください。
『 あなたが大量のデータの中から、必要な情報だけをピックアップし、それをもとに分析や予測を行うという作業 』を。
通常、これは時間がかかり、『 複雑で面倒な作業 』になりがちです。
しかし『 Pandas 』があれば、そのすべてが
『 数行のコード 』で実現可能になります。
不要なデータを削除したり、特定の条件に一致するデータだけを抽出したりする作業が、信じられないほど簡単にできます。
Pandasが特別である理由
具体的に何がPandasをそんなに『 特別なもの 』にしているのでしょうか?
データフレームの基礎
データフレームの特徴
データフレームは、行と列が交差する表形式のデータ構造です。
Excelのスプレッドシートを想像してもらえば分かりやすいでしょう。
各列にはユニークな名前があり、異なるデータ型(数値、文字列、日付など)を持つことができます。
また、データフレームでは、列には列名が、行には行名(インデックス)が付けられており、それぞれの列名や行名を指定してデータを取得し、集計や加工に利用することができます。

列 (Columns):
表の縦のラインです。
カテゴリーを表しており、それぞれには独自の名前がついています。
行 (Rows):
行は表の横のラインです。
上記の画像を参考にしていただくと、名前、年齢、誕生日といった一連の情報が1行にまとめられています
インデックス(Index):
インデックスとは、各行に付けられた番号やラベルのことです。
通常、インデックスは0から始まる番号が自動的に割り当てられますが、日付や他のラベルをインデックスとして設定することも可能です。
データフレームの作成と操作
どのようにデータフレームを作成するかを説明していきます。
心配無用です。
一つ一つのステップをゆっくりと進めていきましょう。
データフレームの作成
ステップ1: Pandasライブラリのインポート
まずは、Pandasライブラリをインポートすることから始めます。
これにより、Pandasの機能を使用できるようになります。
Pandasは、データ分析に必要な様々な機能を提供します。
具体的には、以下のようなことができます。
- データの読み込み・書き込み
- データのクリーニング
- データの集計・分析
- データの可視化
import pandas as pdポイントを解説
ライブラリーをimportする場合は、import インポートしたいライブライリー名 as 短縮名pandasというライブラリをpdという短い名前で使えるようにしています。
これは一般的な慣習で、コードを書く際の手間を省きます。
ステップ2: データフレームのデータを準備する
次に、データフレームに入れたいデータを準備します。
今回は、データをPythonの辞書形式で用意します。
辞書のキーが列の名前に、値がその列のデータになります。
data = {
'Name': ['Tom', 'Nick', 'Kris', 'Jack'],
'Age': [20, 21, 19, 18],
'City': ['New York', 'Los Angeles', 'Chicago', 'Houston'],
'Gender': ['Male', 'Male', 'Male', 'Male'],
'Height': [175, 180, 178, 182],
'Weight': [70, 80, 75, 85]
}
ポイントを解説
6つの異なるキー(’Name’, ‘Age’, ‘City’, ‘Gender’, ‘Height’, ‘Weight’)を持つ辞書dataを作成しました。
つまり、6つの列を持つデータが作成されたことになります。
ステップ3: データフレームの作成
準備したデータを使って、実際にデータフレームを作成します。
これはPandasライブラリのDataFrame関数を使うことで行います。
DataFrame関数は、データをデータフレームに変換するために使用します。
df = pd.DataFrame(data)ポイントを解説
この行では、先ほど作成したdataという辞書をDataFrame関数に渡して、新しいデータフレームdfを作成しています。dfはこれからこのデータフレームを指す名前になります。
ちなみに、pandasをインポートする際に、import pandas as pdと記載しましたが、import pandasとしてもOKです。
しかし、今回の様にPandasライブラリ内の関数やクラスを使用する際に、毎回pandas.をプレフィックスとして付けなければなりません。import pandasとしたなら、
データフレームを作成する際には、以下のようにpdではなく、pandasと略さずに書きます 。df = pandas.DataFrame(data)
これは、コードが冗長になり、タイピングの手間が増えることを意味します。
ですので、効率的に作業を進めるためにもimport pandas as pdの形式が推奨されます。
完成!
以上で、データフレームが完成しました。
作成したデータフレームを見てみましょう。
dfポイントを解説
Google ColabのようなJupyter Notebookベースの環境では、dfと単に記述して実行すると、データフレームはリッチなHTML形式で表示されます。print(df)を使用してもデータフレームは表示されますが、この場合はプレーンテキスト形式での出力となり、HTML形式でのリッチな表示は得られません。
Google Colabを使用している場合、特にデータの探索や分析作業を行う際には、単にdfと記述してデータフレームを表示する方法がおすすめです。
この方法では、データフレームの内容をより直感的に理解しやすくなり、データ分析の作業効率が向上します。
ステップ 1からステップ 3をまとめると
data = {
'Name': ['Tom', 'Nick', 'Kris', 'Jack'],
'Age': [20, 21, 19, 18],
'City': ['New York', 'Los Angeles', 'Chicago', 'Houston'],
'Gender': ['Male', 'Male', 'Male', 'Male'],
'Height': [175, 180, 178, 182],
'Weight': [70, 80, 75, 85]
}
df = pd.DataFrame(data)
df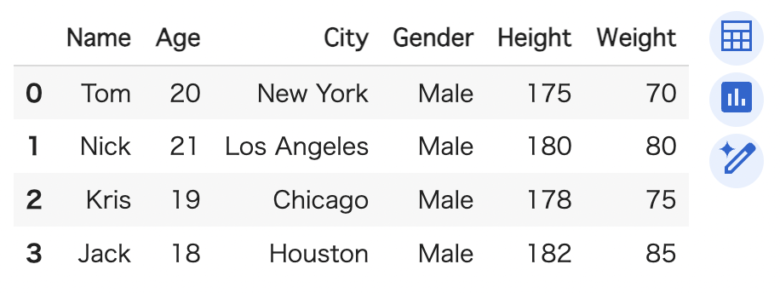
まとめ
今回はpandasとデータフレームとは何かという内容で書かせていただきました。
pythonの辞書を使用し、表形式であるデータフレームを作成することができれば、今後データを分析していく場面で大いに役立つと思います。
今回はデータフレームの作成までの内容としましたが、次回は作成したデータフレームを操作する方法を解説していきたいと思いますので、参考にしてみてください。
この記事が皆様のお役に立てたなら幸いです。

コメント